
Tacotron2
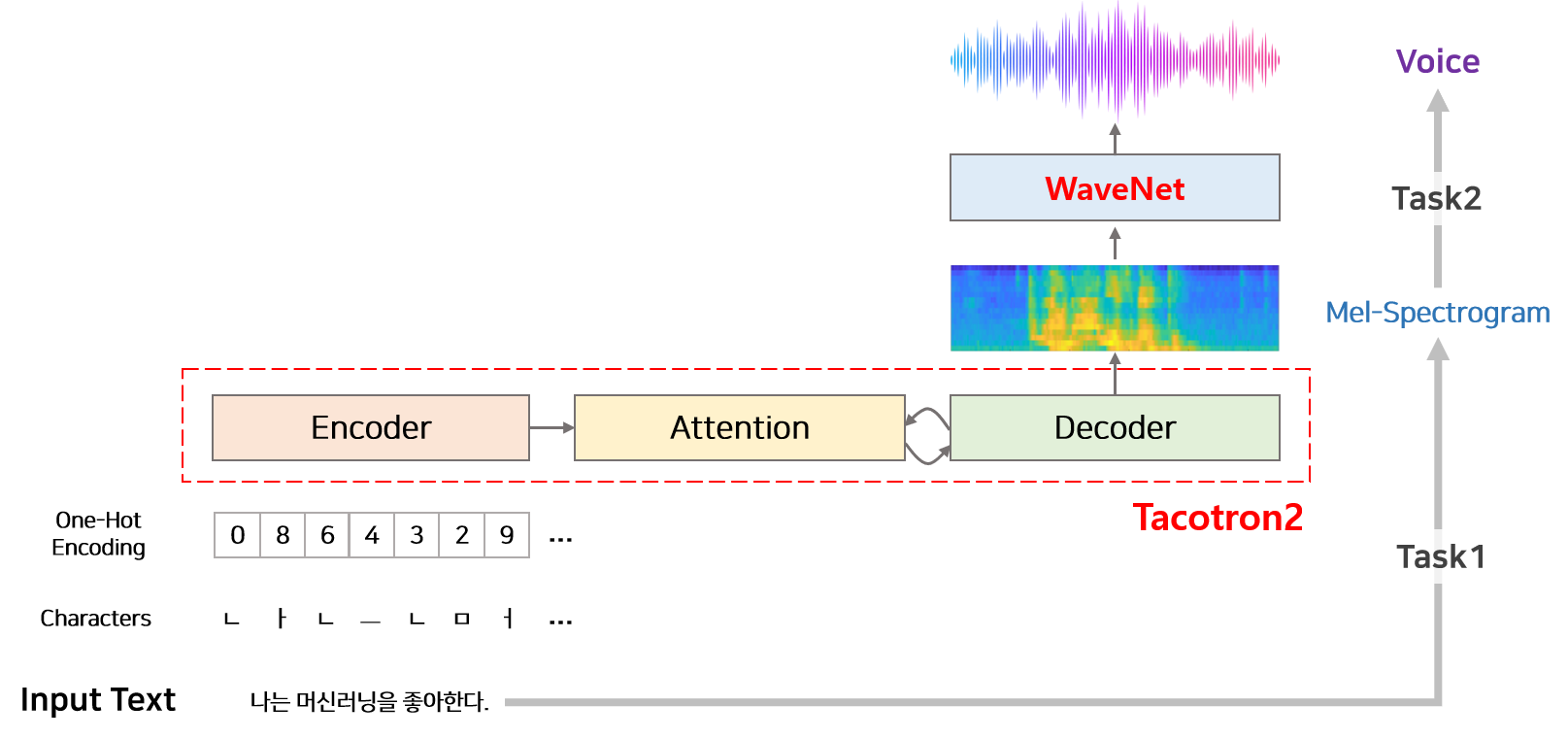
Tacotron2는 mel-spectrograms를 예측하는 sequence-to-sequence 모델이다. 입력된 텍스트를 고정된 크기의 어떠한 방식으로 변환시키는 인코더와 디코더에서 사용할 정보를 인코더에서 추출하여 디코더에게 전달해주는 Attention과 전달된 것을 한 번에 하나의 Spectrogram으로 변환해주는 디코더로 이루어져있다.
최종 Input은 text이고 output은 음성이다.
하지만 앞서 말한것처럼 input으로 text가 들어와서 바로 음성을 생성하는것은 어려운 일이기 때문에 tacotron2에서는 TTS를 두 단계로 나누어 처리한다.
- Task1 : 텍스트로부터 mel-Spectrogram을 생성함
- Task2 : mel-Spectrogram으로부터 음성을 합성함.
Task1은 Tacotron2모델이 담당하고, Task2는 Vocoder로서 WaveNet모델을 변형해서 사용한다.
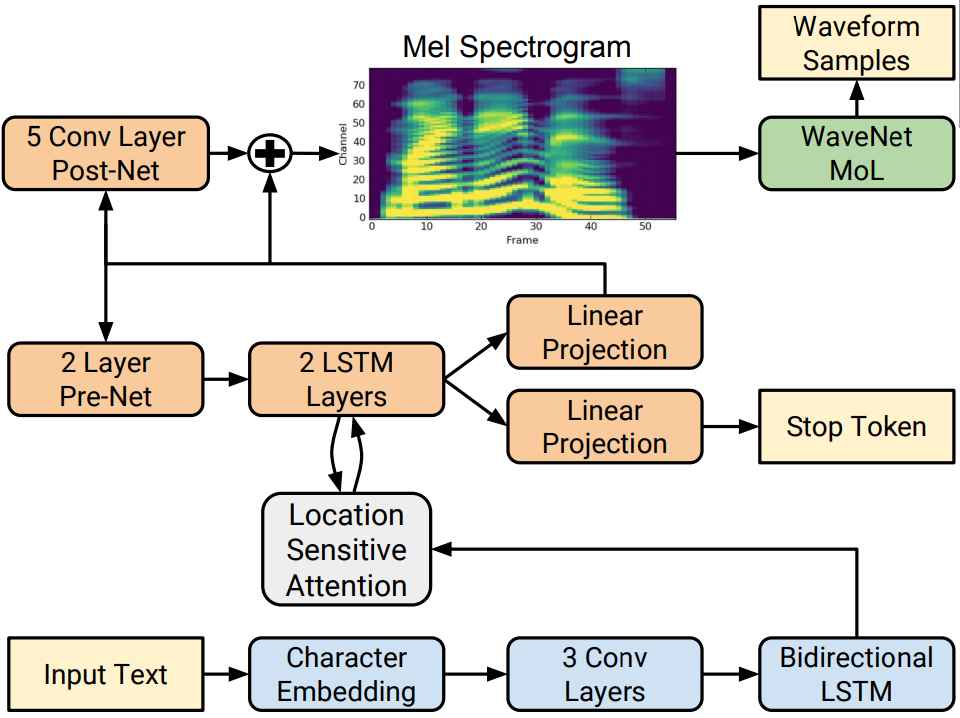
인코더
파란색 박스
디코더주황색 박스
전처리
모델을 학습하기 위해서 input과 output이 한쌍으로 묶인 데이터가 필요하다.
1
2
data/tts_datas/000001.wav|I love you.
data/tts_datas/000002.wav|Nice to meet you.
위와 같은 형태로 저장된 데이터중 텍스트는 character의 형태로 음성은 mel-spectrogram형태로 만들어줘야한다.
우선 영어라면 띄어쓰기를 포함하여 알파벳을 나누는 작업을 한다 예를 들어 첫 번째 데이터 I love you의 텍스트는 ‘I’, ‘l’, ‘o’, ‘v’, … ,’u’ 형태로 변경되어 one-hot-encoding을 적용하여 정수열로 변경한 뒤 다음 모델의 input으로 적용된다.
한국어는 Tacotron2 해당 글을 확인하길 바란다.
음성은 아직 이해를 하지 못하기도 했고 어려운부분이 있어서 일단 넘어가고 나중에 다시 다뤄보기로 하겠다.
Encoder
전처리를 통해 나온 Character타입 input을 총 3개의 단계를 걸쳐 `Encoded feature로 변환하는 역할을 한다.
Attention
Attention은 매 시점마다 디코더에서 사용할 데이터를 인코더로부터 추출하여 가져오는 역할을 한다.
Decoder
Attention을 통해 얻은 데이터를 이전에 전처리 과정에서 생긴 mel-spectrogram을 이용하여 다음 시점의 mel-spectrogram을 생성하는 역할을 한다.
Decoder은 총 4개의 단계를 거쳐서 진행된다.
WaveGlow
Tacotron2 모델을 통해 encoder, attention, decoder과정을 거쳐 얻은 mel-spectrogram을 가지고 음성을 합성하는 모델이다.
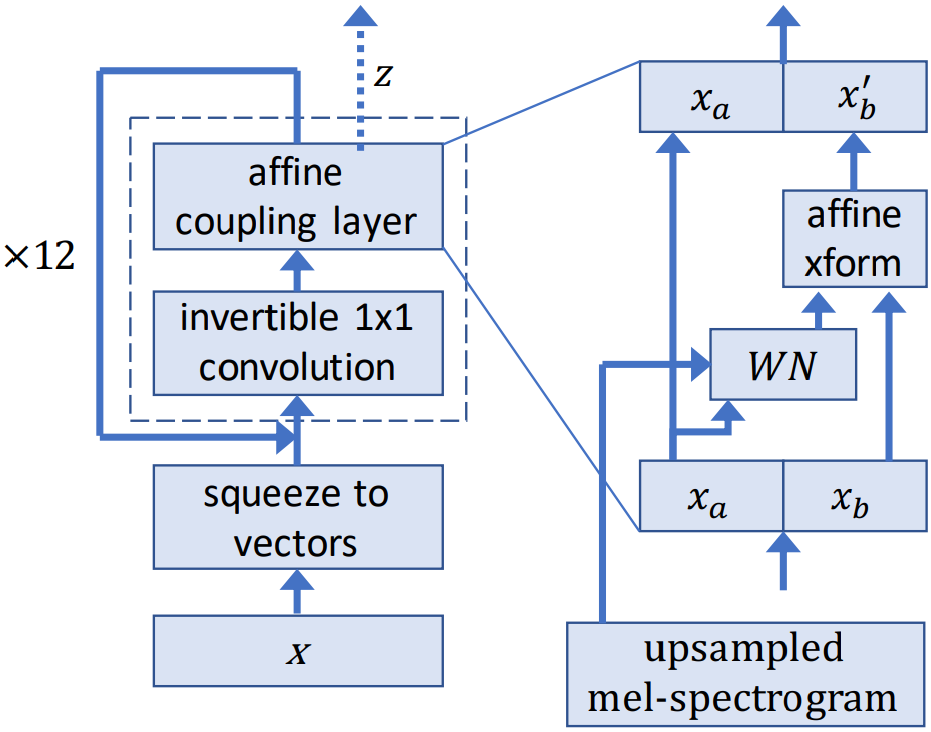 tacotron2 논문설명에서는 mel-spectrogram을 컨디셔닝을 사용하여 가우시안분포에서 오디오 샘플을 생성한다는데 무슨말인지는 잘 모르겠다.
tacotron2 논문설명에서는 mel-spectrogram을 컨디셔닝을 사용하여 가우시안분포에서 오디오 샘플을 생성한다는데 무슨말인지는 잘 모르겠다.
다음 할것
Tacotron2을 코드로 작성해보고 tacotron2에 대해 추가로 공부해보자.