
이번 산업협력프로젝트로 Tacotron2 아키텍처로 한국어 tts 시스템을 만드는 프로젝트를 하기로 했다.
이번 프로젝트로 딥러닝, AWS, WEB 등 아직 배워보지 못한 부분도 많지만 차근차근 하나씩 배워가면서 해보도록 하겠다.
타코트론
먼저, Tacotron2 이란 17년도 구글이 논문에서제안한 Text-To-Speech 모델이다.
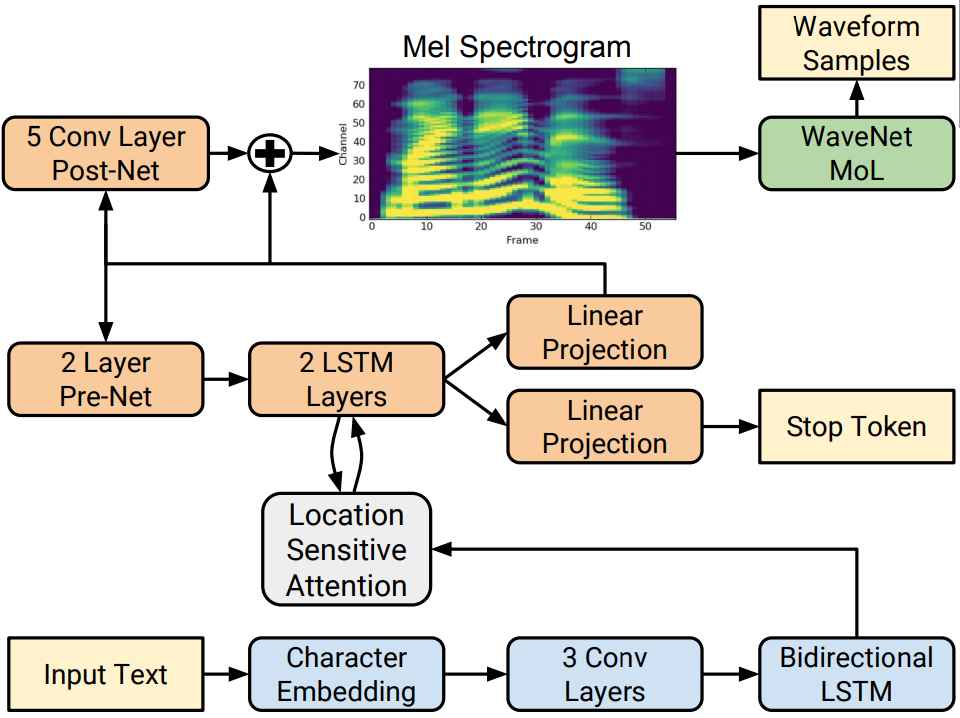
TTS 아키텍쳐는 텍스트에서 Mel-Spectrogram을 생성하는 Mel-Network와 Mel-Spectrogram에서 Audio Signal을 생성하는 Vocoder로 이루어져있다.
Mel-Spectrogram- 음성데이터를 그대로 사용하면 파라미터도 많고 용량도 커져서 분석하기에 적합하지 않기 때문에, 이 음성 데이터를 mel scale로 볼 수 있게하여 주파수를 잘 인식하게 도와주는 것.
NVIDIA Tacotron2
TTS가 어려운점은 신호처리 개념이 많이 필요하기 때문이다. 음성처리 같은 경우는 librosa 라이브러리를 통해 Mel-Spectrogram같은 주파수뽑아서 바로 사용해도 성능에 크게 문제가 있지는 않지만 TTS 시스템은 좀 더 정교하게 뽑아줄 필요가 있다.
이때 사용하는것이 NVIDIA Tacotron2이다. NVIDIA Tacotron2는 오픈소스로 학습 최적화를 잘 해놔서 학습속도도 빠르다는 장점이 있다.
NIVIDIA Tacotron2 이 주소를 들어가면 자세히 볼 수 있다.
NVIDIA Tacotron2 Data Format
NVIDIA Tacotron2는 아래와 같은 Data Format이 필요하다.
1
2
data/tts_datas/000001.wav|튜닙은 자연어 처리 테크 스타트업입니다.
data/tts_datas/000002.wav|타코트론은 대표적인 음성합성 모델이에요
[오디오경로]|[텍스트] 를 |로 구분한 txt파일이 필요로하다.
Korean
NIVIDIA Tacotron2의 구현체는 LS Speech를 제공한다. LS Speech는 영어 데이터셋이기 때문에 한국어 데이터 셋인 KKS를 사용하기 위해서는 수정이 필요하다.
우리가 구현해 줘야할 함수는 ` text_to_sequence 함수이다. 해당 함수는 매개변수로 어떠한 텍스트를 받아 토크나이징 및 숫자` 표현으로 인코딩해주는 역할이다.
1
2
3
4
5
def text_to_sequence(text: str):
...
...
print(text_to_sequence("안녕하세요"))
위 예시를 보면 text_to_sequence 함수에 안녕하세요 텍스트를 입력으로 받아 토크나이징 및 숫자로 표현해준다.
text_to_sequence
크게 3가지 기능을 수행한다.
- 텍스트 클리닝
- 토크나이징
- 숫자 표현으로 인코딩
텍스트 클리닝
어떤 문자열이 텍스트로 들어올지 모르기 때문에 허용 가능한 문자를 미리 정의해두는 것이다.
한국어로 TTS를 구현하려면 문자를 (초성, 중성, 종성)단위로 쪼개야한다.
감이라는 문자는ㄱ ㅏ ㅁ으로 쪼개야한다.
- NFKD Normalize
1
2
3
4
5
6
7
8
9
import unicodedata
text = "텍스트박스"
text = unicodedata.normalize('NFKD', text)
for t in text:
print(t, end=" ")
# ㅌ ㅔ ㄱ ㅅ ㅡ ㅌ ㅡ ㅂ ㅏ ㄱ ㅅ ㅡ
위 방식으로 초성, 중성, 종성으로 분리가 가능하다.
토크나이징 과 인코딩
앞서 텍스트 클리닝으로 텍스트를 분해해 놨다. 텍스트를 for문만 돌리면 쉽게 토크나이징이 가능하다.
보통 토크나이징 하면서 인코딩도 같이 진행을 하는데, 인코딩을 하기 위해서는 Vocabulary를 먼저 정의해야합니다.
- 스페셜 토큰: _, ~ (pad, eos)
- 초성: 0x1100 ~ 0x1113
- 중성: 0x1161 ~ 0x1176
- 종성: 0x11A8 ~ 0x11C3
- 알파벳: ABCDEFGHIJKLMNOPQRSTUVWXYZ
- 숫자: 0123456789
- 특수문자: ?! (띄어쓰기 포함)