
Information
시작하기 앞서 혼자 공부하는 데이터분석책을 보고 공부했습니다.
목표로는 이 책을 어느정도 공부하면서 스스로 데이터를 찾아서 분석해보는것으로 세우고 시작하겠습니다.
데이터 분석(Data Analysis)
데이터 분석은 단순히 한 마디로 정의하기는 어렵다. 물론 사전적인 의미로는 데이터는 자료, 정보를 의미하고 분석은 복자한 대상을 정확하게 이해하기위해 단순한 요소로 나누어 설명하는것을 의미하게 된다.
위키피디아에서 정의된 데이터 분석은 유용한 정보를 발견하고 결론을 유추하거나, 의사 결정을 돕기 위해 데이터를 조사, 정제, 변환하여 모델링 하는 과정을 말한다.
데이터 분석과 함께 자주 언급되는 용어에는 데이터 과학이다. 보통은 데이터 분석과 데이터 과학은 동일시 취급되지만, 정확히는 데이터 과학은 통계학, 머신러닝, 데이터마이닝등 같은 큰 개념으로 이루어져있다.
데이터 과학(Data Science)
데이터 과학자 지 리가 말하길 데이터 과학은 데이터 세계와 비즈니스 세계를 이어주는 다리 역할이다. 데이터 과학을 통해 소프트웨어나 제품은 개발할 수 있지만 이것이 전부가 아니며, 머신러닝, 통계학, 그래프 그리기 등 많은 것을 포함하는 분야이다.
- 데이터 분석
- 올바른 의사결정을 돕기위한
통찰에 집중함
- 데이터 과학
- 한 걸음 더나아가 문제 해결을 돕기아한 최선의
솔루션을 제공해준다.
언어
데이터 분석에 사용되는 언어는 Python, R 이다. 물론 데이터가 데이터베이스 형태로 존재한다면, SQL도 사용할 수 있지만 SQL은 시각화나 통계적인 분석에 어려움이 존재한다.
이 책에서 사용되는 언어는 Python이며, 사용되는 프로그램은 구글 Colab을 사용하지만 Visual studio Code가 편하기에 Code로 사용하기로 한다.
환경만들기
Visual Studio Code홈페이지에 들어가면 아래와 같은 사진이 나와 다운로드를 눌러 설치를 진행하면된다.
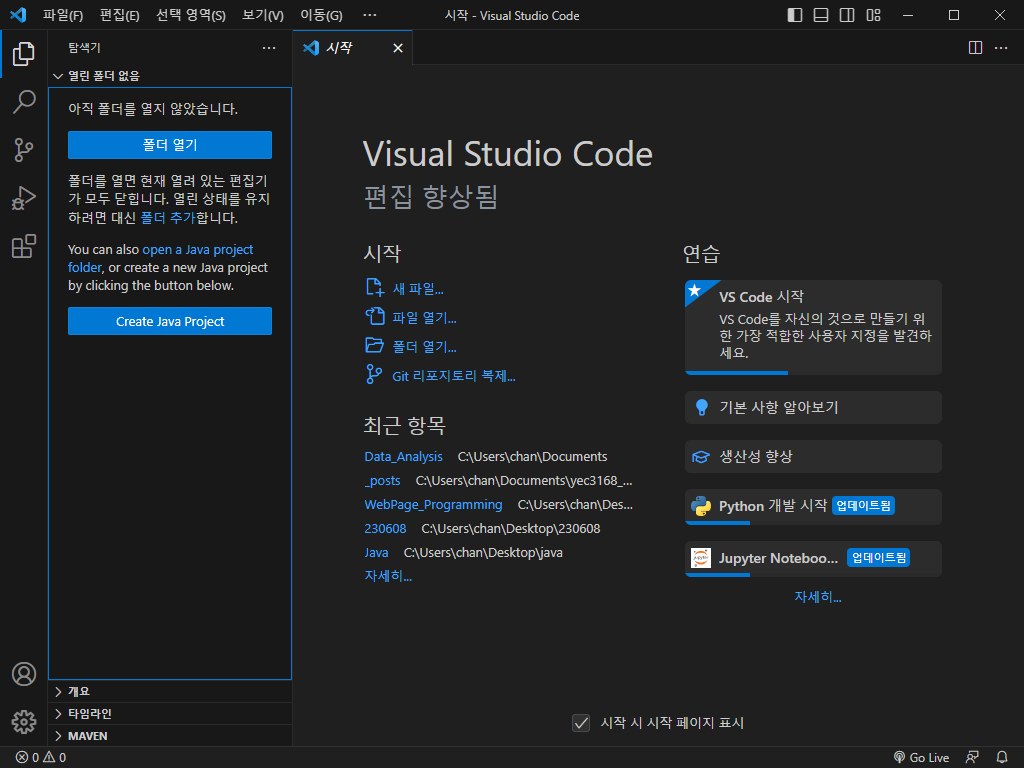
제대로 다운이 완료되고 실행시켜보면 사진처럼 나오게 된다.
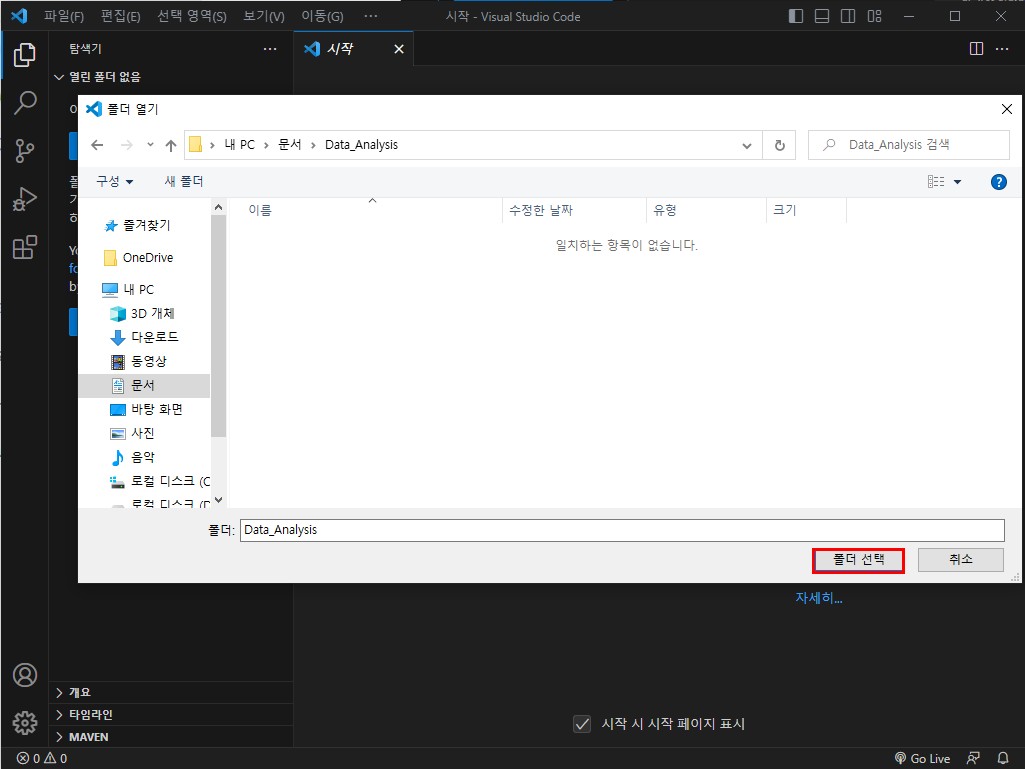
여기서 폴더열기를 누르고 C:\Users\사용자 이름\Documents\위치에 Data_Analysis라는 새로운 폴더를 만들고 폴더 선택을 누르면 된다.
무사히 마치면 확장으로 들어가 마켓플레이스에서 python을 설치하자 가장 최신버전으로 설치하면된다.
데이터 세트 받아오기
폴더를 생성했으면 데이터 분석에 사용할 데이터를 받아와야한다. 책에서 사용하는 데이터 세트는 정보나루에 있는 서울특별시교육청남산도서관 장서/대출 데이터이다.
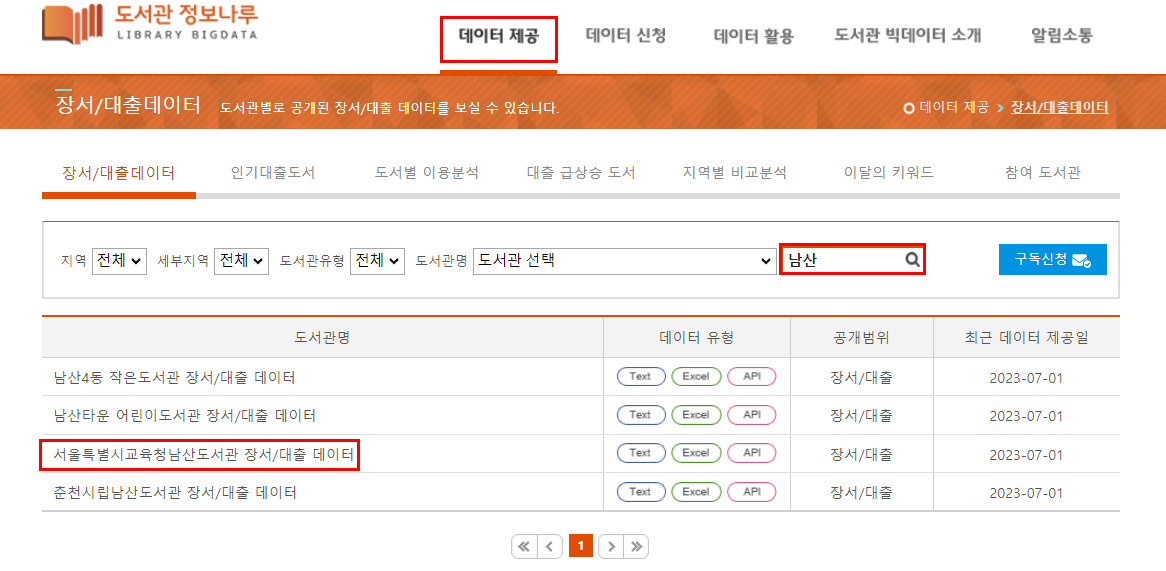
위 사진처럼 데이터 제공에 들어가 검색창에 남산 검색하고 해당 데이터를 CSV형태로 다운받자.
다운받은 파일은 이전에 만들었던 Data_Analysis폴더에 넣자.
더 많은 데이터들을 찾고 싶다면 공개 데이터 세트 참고.
명령어
이제 Data_Analysis폴더에 파일을 하나 만들어보자. 이름은 test.ipynb로해서 만들면 된다.
open()
CSV 파일은 텍스트 파일이므로 open()함수를 통해 읽을 수 있다.
1
2
with open('./data/서울특별시교육청남산도서관 장서 대출목록 (2023년 06월).csv') as f:
print(f.readline())
open 파일은 UTF-8 형식으로 저장되어있다고 가정하지만, 다운받은 CSV 파일의 인코딩 방식이 다른거 같다.
chardet_detect()
chardet 패키지의 chardet_detect()함수는 파일의 인코딩 방식을 확인한다.
1
2
3
4
import chardet
with open('./data/서울특별시교육청남산도서관 장서 대출목록 (2023년 06월).csv', mode='rb') as f:
d = f.readline()
print(chardet.detect(d))
-> {‘encoding’: ‘EUC-KR’, ‘confidence’: 0.99, ‘language’: ‘Korean’}
인코딩 결과를 보면 EUC-KR로 되어있는걸로 볼 수 있다.
인코딩 형식 저장하기
1
2
with open('./data/서울특별시교육청남산도서관 장서 대출목록 (2023년 06월).csv', encoding="EUC_KR") as f:
print(f.readline())
위 방식으로 인코딩 형식을 따로 지정함으로써 파일을 읽어 올 수가 있다.
read_csv()
판다스에서 CSV을 읽어올때 사용하는 함수이다.
1
2
import pandas as pd
df = pd.read_csv('./data/서울특별시교육청남산도서관 장서 대출목록 (2023년 06월).csv', encoding="EUC-KR", low_memory=False)
low_memory=False로 해서 나누어 읽지 않고 한번에 읽는다. 하지만 low_memory를 사용하게 되면 한 번에 읽어오기 때문에 메모리 차지가 심하다. 이런 문제점을 보안하기 위해 사용하는 것이 dtype 매개변수로 데이터 타입을 지정하는 것이다.
dtype은 각 열의 타입을 지정해주는 것으로 경고가 발생한 열에 타입을 정해 데이터 타입을 자동으로 찾지 않도록 한다.
1
2
df = pd.read_csv('./data/서울특별시교육청남산도서관 장서 대출목록 (2023년 06월).csv',
encoding="EUC-KR", dtype={'ISBN': str, '세트 ISBN': str, '주제분류번호':str})
to_csv()
데이터프레임을 csv로 저장하는법
1
df.to_csv('./data/test.csv')
인덱스를 제거하여 저장할 수도 있다.
1
df.to_csv('./data/test.csv', index =False)
indexl_col 매개변수
csv파일에 이미 index가 존재하면 index_col를 사용하여 추가되는 index를 제거한다. 저장된 test.csv파일에 첫번째 열에 인덱스가 존재하므로 index_col = 0 매개변수를 추가한다.
1
df = pd.read_csv('./data/test.csv', index_col=0)
판다스
CSV파일 같은 텍스트 파일을 데이터프레임라는 표 형태로 저장해주는 것.
시리즈
1차원 배열을 생각해보자. 1차원 배열의 원소들은 모두 같은 타입을 가진다. 데이터프레임 구조를 보면 아래와 같은데

2번째 행만 봐도 정수와 문자열이 섞여 있는구조로 이루어져있다. 데이터프레임은 열마다 다른 데이터타입을 사용할 수 있고, 각 열을 선택하면 이것을 시리즈 객체라고 한다.
공개 데이터 세트
국내 사이트
- 공공데이터
- 행정 안전부가 제공하는 공공데이터 통합 제공시스템
- 통합데이터 지도
- 국가와 민간분야에서 운영 중인 여러 빅데이터 플랫폼의 데이터를 한곳에서 검색할 수 있는 서비스
- AI 허브
- AI 통합 플랫폼으로 다양한 AI학습용 데이터를 제공
- 국가통계포털
- 경제, 사회, 환경 등 30개의 분야의 국내외 통계 데이터를 찾을 수 있음.
해외사이트
- 구글 데이터 세트 검색
- 무료로 사용할 수 있는 데이터를 제공하는 검색엔진
- 캐글 데이터 세트
- 머신러닝 경진 대회 플랫폼으로, 경진대회에서 사용한 데이터셋을 확인할 수 있다.
- 위키피디아 머신러닝데이터 세트
- 머신러닝 연구에 널리 사용되는 데이터 세트가 주제별로 정리되어 있다.
- 아마존 웹서비스 오픈데이터
- UCI 머신러닝 데이터 저장소